Rebalancing Pods with Descheduler¶
Kubernetes schedules pods when they're created. It picks the best node at that moment based on resources, affinity, taints, and topology. But it never revisits that decision. Over time, nodes get unbalanced. A node that was empty during a deploy gets overloaded after a few scaling events. Another node sits mostly idle because its pods got evicted and rescheduled elsewhere.
Descheduler fixes this. It runs periodically, evaluates the cluster state, and evicts pods that shouldn't be where they are. The regular scheduler then places them on better nodes.
How it runs¶
In my homelab, Descheduler runs as a Deployment (not a CronJob) with a 5-minute cycle. Every 5 minutes it evaluates the cluster and evicts pods that match any of the enabled policies. Running as a Deployment means it also exposes metrics continuously, which Prometheus scrapes via a ServiceMonitor.
It runs on the small tier node. Minimal resources: 25m CPU, 64Mi memory.
The policies¶
Six plugins enabled, split into two categories:
Balance plugins redistribute pods across nodes:
LowNodeUtilization. If a node is using less than 20% CPU and 20% memory, it's considered underutilized. If another node is above 50%, Descheduler evicts pods from the overloaded node so the scheduler can place them on the underutilized one. This keeps workloads spread more evenly.
RemoveDuplicates. If two replicas of the same Deployment end up on the same node (which can happen after a node restart or scaling event), one gets evicted so the scheduler can spread them.
RemovePodsViolatingTopologySpreadConstraint. If pods violate their topology spread constraints (e.g., should be spread across nodes but ended up on the same one), they get evicted and rescheduled properly.
Deschedule plugins fix pods that are in the wrong place:
RemovePodsHavingTooManyRestarts. Pods with more than 10 restarts (including init containers) get evicted. A fresh start on a potentially different node sometimes fixes issues caused by local state or node-specific problems.
RemovePodsViolatingNodeAffinity. If a pod's requiredDuringSchedulingIgnoredDuringExecution affinity no longer matches the node it's on (can happen after node label changes), it gets evicted.
RemovePodsViolatingInterPodAntiAffinity. Pods that violate inter-pod anti-affinity rules get evicted so the scheduler can fix the placement.
Extra RBAC for PVCs¶
The default Descheduler RBAC doesn't include permissions to read PersistentVolumeClaims. Some eviction decisions need to check if a pod has local storage that would be lost. I added a ClusterRole and ClusterRoleBinding that gives the Descheduler read access to PVCs.
Observability¶
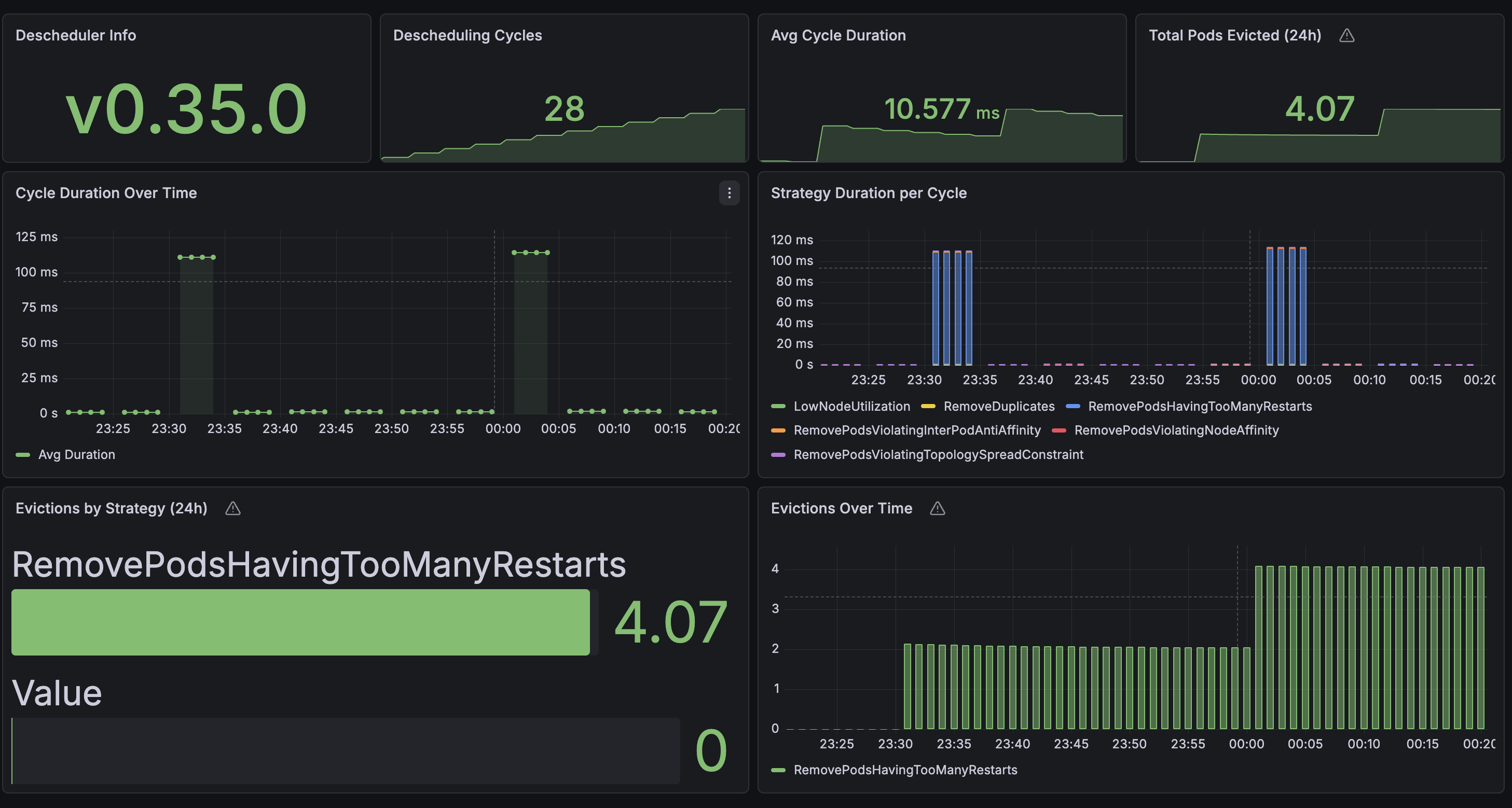
A ServiceMonitor scrapes Descheduler metrics into Prometheus, and a Grafana dashboard (loaded via ConfigMap) shows eviction counts, policy activity, and cycle duration. This is how I know the Descheduler is actually doing something useful and not just evicting pods for no reason.